
 As I discussed last week, Paul Meehl showed, in 1954, in a book called Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence, that various algorithms performed as well as clinical predictions, although he didn’t use the word “algorithm”. He had been stimulated to investigate this question by a paper in the American Journal of Sociology, in which the psychologist Theodore R Sarbin showed that predictions of academic success made on the basis of case studies that took into account many variables were no more accurate than predictions using statistical methods that relied on only two variables.
As I discussed last week, Paul Meehl showed, in 1954, in a book called Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence, that various algorithms performed as well as clinical predictions, although he didn’t use the word “algorithm”. He had been stimulated to investigate this question by a paper in the American Journal of Sociology, in which the psychologist Theodore R Sarbin showed that predictions of academic success made on the basis of case studies that took into account many variables were no more accurate than predictions using statistical methods that relied on only two variables.
Meehl emphasized his results again in a paper published in the Journal of Personality Assessment in 1986, titled “Causes and effects of my disturbing little book,” and since then a meta-analysis by Grove et al has shown that, on average, “mechanical prediction techniques” are about 10% more accurate than clinical predictions and in most studies were at least as good as clinical prediction, or outperformed it (See figure below). In only a few studies were clinical predictions substantially more accurate than mechanical predictions, or actuarial methods, as Meehl and his colleagues called them.
Clinicians have generally been upset by these results and the implication that mechanical or actuarial, i.e. algorithmic, methods are at least as good as clinical judgement, which they typically are when the outcomes are poorly structured. Meehl, for example, reported that “half the clinical faculty at one large Freudian oriented midwest university were plunged into a 6-month reactive depression as a result of my little book.” But in order to interpret the import of these results it is necessary to remember what an algorithm is—a formula for working something out. If the thing to be worked out repeatedly, or at least often, yields to the method that the algorithm uses, and if no particular skill is needed, there is no reason why the algorithm should not be as good as any cognitive method. Like using Google or the OMIM (On-line Mendelian Inheritance in Man) database as diagnostic tools, as some have done. Indeed, one would expect algorithms generally to perform better, since we know that the human brain is a relatively poor computer and that human cognition can be adversely affected by, for example, lack of sleep, hunger, or an adverse recent experience, as computers are not. Experts may also be distracted by trying to take into account features of a case that are irrelevant.
Alan Turing used computer algorithms to crack the Enigma code. Google and other search engines and Facebook and other social media outlets all depend on algorithms. But we are accustomed to using algorithms to help us to crack problems that we know are beyond our own computational powers. It’s when the algorithms start doing things that we do ourselves, but much better, that we start to feel uneasy. Like the computer algorithm called Watson that beat two champion players of the not altogether straightforward US television quiz game Jeopardy and has since been shown to have medical applications. Or the simple algorithm that accurately predicts the quality and value of a bottle of wine better than expert wine tasters.
In 1994 Chinook, which played draughts (checkers), became the first computer program to win a human world championship. Then, in 1997, an IBM computer, Deep Blue, beat the world chess champion, Garry Kasparov over six games, winning two, losing one, and drawing three. Only 12 years before, Kasparov had beaten 32 computers in a simultaneous display. Kasparov’s recent book, Deep Thinking, describes what it’s like to be beaten by an algorithm.
Even more striking is the success in 2016 of a machine, AlphaGo, that beat the strongest player in the world, Lee Sedol, at the most difficult mind game in the world, Go.
Meehl called the preference for clinical rather than mechanical methods “using our heads instead of the formula”. The word formula comes from a supposed IndoEuropean root MERBH, to shine and, because what shines is easily seen, to appear or take shape. This gives the Greek word μορϕή, form, giving us amorphous, morphology, and metamorphosis. Metathesis morphed the Greek “morph” into the Latin “forma”, appearance or beauty, giving us form and format, conform, deform, inform, perform, platform, proforma, reform, transform, uniform, and the vermiform appendix. “Formula” is its diminutive, a little beauty, so to speak.
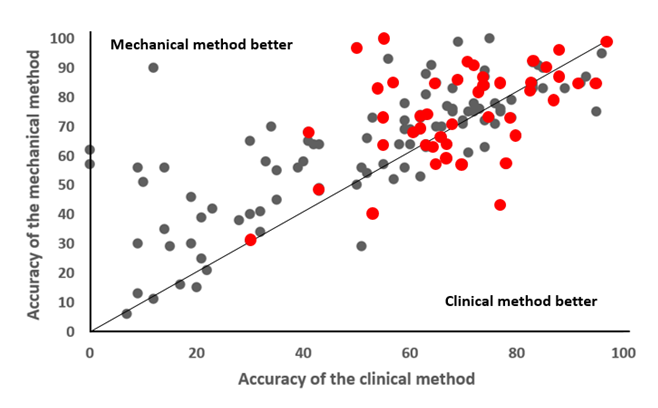
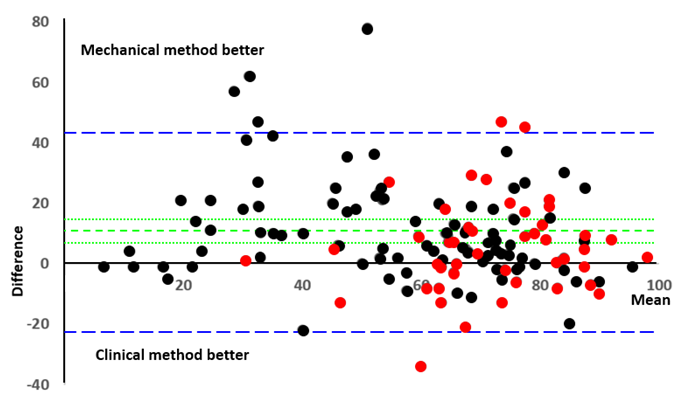
Figure. A diagrammaric analysis of the results of Grove et al. (2000), who compared mechanical and clinical methods in nearly 140 studies
Top panel: A scattergram comparing the accuracies of the two methods, measured by percentage “hit rates” and correlations (which have been multiplied by 100 to allow direct comparison); the line is the line of equality; the red symbols signify studies of diagnostic techniques
Bottom panel: The same data analysed according to the method of Bland and Altman (1986), plotting the difference between each pair of measurements against the average of the two; the blue lines show the limits of agreement at two standard deviations beyond the mean; the green lines show the mean difference between the two methods (9.6% in favour of the mechanical methods) and the 99% confidence interval of the mean (5.9, 13); arcsin transformation of the values made no appreciable difference (mean 9.5%, 99%CI 5.6, 13)
Jeffrey Aronson is a clinical pharmacologist, working in the Centre for Evidence Based Medicine in Oxford’s Nuffield Department of Primary Care Health Sciences. He is also president emeritus of the British Pharmacological Society.
Competing interests: None declared.